- 주제
1) 데이터 레플리케이션=복제에 대해.
2) 데이터의 일관성에 대해.
01. 분산시스템에서 복제란 무엇인가?
: 서버의 사본을 여러개 만드는 것.
분산시스템 자체가 서버를 여러대 만드는 것이기 때문에 복제 아닌가?
stateless를 고려하자. 서버 여러대에 저장하더라도 각각의 서버가 동일한 데이터를 저장하고 있다고 할 수는 없다.
레플리케이션은 단순히 서버 여러대를 사용하고 있는 것이 아니고, 완전히 동일한 서버가 여러대가 있어야 한다.
즉, 분산시스템 = stateless, stateful한 것 모두 포함.
레플리케이션은 그 중에서 stateless한 서버(완전히 서로 동일한 서버)를 말한다.

- 진한게 원래 서버, 나머지는 백업용.
원래의 서버가 고장났을때 다른 둘 중 하나를 사용.
즉, 장애가 발생했을 때 대처하려고 레플리케이션 활용.
1. 왜 복제를 사용하는가?
1) 고가용성: 장애 발생시, 성능이 느려진다 해도 상관없이 일단 기능이 작동하는 것.
2) fault tolerance: 장애가 발생해도 동일한 성능을 발휘하는 것.
결국 레플리케이션의 기본적인 목적은 장애 발생시의 사본을 만들기 위함이다.
3) High performance: 복제본이 동일한 서버, 동일한 데이터라면. 3M이 있고 각각 1M, 1M, 1M이라면. 나머지 서버들로 서비스를 처리하면 훨씬 효율적이다.
그러나 직관적으로는 로드 밸런스 등으로 흩뿌리면 되겠다고 생각하지만 - 레플리케이션은 데이터를 복제한 것이기 때문에: '쓰기' 요청을 받아 값이 변경되면 -> 모든 서버의 데이터가 동시에 변경될 수 없기 때문에: 일관성 없는 읽기가 발생해버린다. (=최신값이 아닌 올드값을 받을 가능성 있음.)
* 제작년에 카카오가 임대해서 쓰고 있는 데이터센터에서 화재가 발생하여 서비스 작동이 안됨. 복구까지 127시간.
원인이 데이터센터 '이중화 미흡'. (=두개를 만드는 것, 복제본을 만드는 것.)
* 정부24 사이트 마비. 카카오가 사기업의 서비스지만 전국민이 사용하는 만큼 국가기관망에 가까운데 이래도 되냐? 하지만 진짜 국가기관망인 민원 시스템이 마비되고 복구하는데 1~2주 소요. 동일하게 이중화 미흡.
-> 왜 안 했어?
이론적으로는 장애 발생시에만 도움이 되기 때문에 사람들이 생각하기에는 아까웠다.
기본적으로 하나만 쓰고 나머지는 백업이기 때문에: 서버 한대만으로도 평소에는 아무 문제 없이 잘 돌아간다. 확률 낮은 사건에 대비해서 서버를 더 마련하면 비용이 서버의 수만큼 배로 는다.
* 보안도 결국 비용. 일어날 확률이 극히 낮음. 보안 관련 솔루션 탑재/기술 도입/인력 채용은 회사 입장에서 메인 서비스를 운영하는 데에는 아무 상관 없음. 보안과 관련된 곳에서는 비용 투자를 별로 하고싶어하지 않음.
보안 관련 대기업 없음. 필요 역량은 수준 높음. 우리나라 상대적으로 처우 안좋음. 고객사의 입장에서 보안은 비용. 시장에서의 보안 회사들의 수익이 낮을 수밖에 없는 구조.
네트워크쪽 관제 업무, 관리 업무 등 또한 학교 입장에서는 비용.
클리셰적인 밈 - 사고가 터지면 미리 대처하지 못했냐/터지지 않으면 너희들은 왜 있냐.
결국 사기업에도 공기업에도 안되어있는게 현실.
2. 복제를 몇번 했는지에 따라 장애를 견딜 수 있는 정도가 달라진다.
n개의 레플리카는 n-1개의 장애를 견딜 수 있다.
즉 n이 3이면 2개의 장애를 견딜 수 있다는 것. (하나는 살아야 작동한다.)
* 일반적으로 레플리카를 몇개를 만드나요?
일반적으로 n은 3, 5, 7을 많이 사용한다. 홀수 계열.
기본적으로 삼중화를 진행.
어차피 장애가 발생할 확률이 낮으면 이중화만 해도 충분한 거 아닌가?
n이 2일때와 3일때 장애 발생 대처 수준이 급격하게 달라진다. 최대한 회사는 안 쓰고 싶어 하니까 3개를 사용.
3. 단순히 백업의 용도가 아니고 연산 수행이 가능하다면?
레플리카의 수가 많을수록 좋다.
4. 레플리카의 세분성
1) Intra-server
- RAID.
하드디스크에 데이터가 저장되어 있을 때, 디스크를 복제해서 그 디스크에 완전히 동일한 데이터를 저장해두면, 하나가 고장나도 다른 것으로 사용이 가능한 것.
개인 사용자는 RAID를 쓸 일이 없다. 장애가 발생할 일이 거의 없기 때문에 - 고장나기 전에 변경한다.
그러니 데이터센터에서 사용한다. 24시간 돌아가기 때문에.
즉, 단일서버 안에서도 레플리케이션이 존재한다.
2) Inter-rack scale
랙에 서버 여러개가 들어가는데, A서버와 B서버가 동일한 데이터를 저장하고 있다고 하면 - 랙 스케일 레플리케이션.
단순히 서버 장애가 발생한것에 대해서는 대처 가능하지만: TOR스위치가 고장났거나 멀티탭의 전압이 터졌을 때 - 랙의 서버가 다 죽어버린다. 이때는 옆에 있는 랙으로 서비스한다.
3) Inter-data center
그 시설에 장애가 발생한 것에는 대응을 못 한다.
완전히 다른 지역에 동일한 데이터센터를 건설한다.
4) Geo-distributed replication
한국과 미국 사이에 있는 해저 케이블을 상어가 뜯어먹었다고 하자.
레플리카 하나는 한국에, 하나는 미국에 두면 대처가 가능하다.
- 조선왕조실록
사대 사고에 보관: 전쟁/화재 발생시에 소실되지 않도록.
임진왜란 발생 - 실제로 불에 타버렸지만 다행히 살아남은 것들이 있었음. 5대 사고로 산속 깊은 곳에 보관.
시간이 흘러 지금은 태백산 사고본과 정족산 사고본만 남았다.
역사적으로 레플리케이션이라는 것은 많이 사용되었던 컨셉이며 실제로 효과가 있었다.
02. Replicated stroage
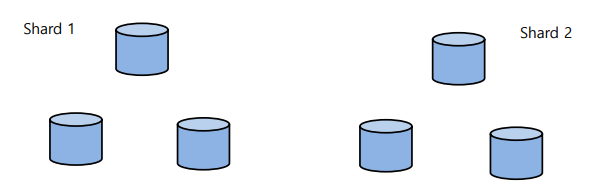
- n-way relpication: 각각의 Shard를 n개의 서버로 복제한 것.
1. 리더 베이스 레플리케이션 Leader-based replication

1) 하나의 리더와 다수의 팔로워로 구성된다.
리더는 모든 요청을 처리하고, 팔로워들은 쓰기 요청만 처리한다.
- Active stanby = 활성화 대기.
- 백업 = Followers.
2) 마스터-슬레이브 구조라고 오랫동안 불려왔다. 부르는 용어와 명칭이 굉장히 다양하다 - 산업계에서는 용어가 통일되어 있지 않기 때문에.
- 리더가 레플리카를 레플리케이션 그룹이라고 부른다. 맨 위의 경우 2개의 레플리케이션 그룹이 존재한다.
2. 프라이머리 백업 Primary-Backup

: 전형적인 리더 베이스 레플리케이션이다.
- 읽기/쓰기 요청을 모두 리더가 전달한다.
- 팔로워들은 백업을 위해 존재한다.
모든 읽기 요청은 리더가 처리한다.
쓰기 요청은 무조건 리더에게 가고, 리더는 바로 답장하지 않는다.
모든 레플리카가 동일한 데이터를 보유하고 있어야 하기 때문에, 리더가 자신의 데이터를 수정하고 팔로워들에게 전파해서 데이터 수정 명령을 내린다. 팔로워들이 전부 업데이트하고 업데이트 소식을 리더에게 전송(ACK)한다.
전부 받고서야 Commit한다.
클라이언트 입장에서는 읽기 요청을 보냈더니 읽기에 대한 답장은 하나였고, 쓰기에 대한 요청도 보냈더니 쓰기 요청도 하나가 온 셈이다. 즉, 몇개의 복제본을 가지고 있는지 클라이언트는 모른다.
가장 심플한 구조이다.
누군가가 레플리케이션 아키텍처를 물어보면 가장 기본적인 구조인 이것을 설명한다.
- 단점: 리더 혼자서만 요청을 처리. Throughput이 리더의 성능에 의해 제한. 즉, 레플리카의 수와 상관없이 성능은 무조건적으로 하나뿐이다.
- 리더 일렉션Leader election이 필요. 리더가 죽었을 때 누굴 다음 리더로 추대할 것인가? 에 대한 선출 구성을 가지고 있어야 함. 그 우선순위가 존재한다.
- 장점: 클라이언트가 항상 최신의 데이터를 읽어올 수 있다. 항상 읽기 요청은 최신의 데이터만 읽을 수 있다.
실제로 레플리케이션의 가장 어려운 점은 데이터 동기화-일관성이다.
3. Chain Replication

읽기와 쓰기를 담당하는 리더를 분리한다. 앞도 리더, 뒤도 리더.
체인이라는 것은 엮는 것이다. 모든 레플리카들을 체이닝한다.
1) 쓰기 요청이 들어오면 헤드에 있는 리더로 들어가서 자신의 값 업데이트 - 다음의 값 업데이트 - 반복.
2) 읽기는 꼬리로 들어가서 꼬리로 나간다.
- 장점: 쓰기 요청을 처리하기 위해서 리더가 여러개의 팔로워들에게 뿌리고 수집받는 과정이 없어진다.
레플리카가 4대가 있다고 가정하면 (1) 쓰기 요청 받음, (2) n개의 업데이트 메세지가 필요, (3) 업데이트 완료 메세지 n개를 받아야 함, (4) 클라이언트에게 리더가 커밋함.
즉 2n+2만큼의 요청을 처리해야 했다. <-> head가 하나 받으면, 옆으로 넘겨주고, 끝. 커밋은 tail이 한다.
3) 리더에게 부과되는 요청의 수가 현저하게 줄어든다. 요청 부과가 분산되는 효과.
- 원래 장애가 발생했을 때: 쓰기와 읽기가 동시에 작동하지 않았다.
테일에 장애가 발생하면: 읽기/쓰기가 안되지만,
헤드만 장애가 발생하면: 읽기는 여전히 가능하다.
- 순차적으로 실행하기 떄문에 강력한 일관성(데이터 동일성)을 가진다.
- 단점: 리더의 성능에 기대어 처리량이 정해진다는 한계점.
4. Leaderless replication
Q. 어떻게 하면 레플리케이션을 함과 동시에 다른 레플리카들도 활용할 수 있을까?
A. 리더가 없으면 된다.

1) 장점: 리더 일렉션이 없다.
새로운 리더를 결정해야 하기 때문에 - 그 결정 시간동안 서비스 동작 불가능.
= 다운 타임이 없어졌다. fault tolerance가 더 좋아진다.
2) 모든 레플리카가 읽기 요청을 처리할 수 있다. 처리량이 단일 레플리카로 한정되지 않는다.
3) 모든 레플리카가 쓰기 요청을 처리할 수 있다.
4) 문제
- Read-write conflicts
- Inter-write conflicts
- 가장 최신의 연구: Hermes, LetLR.
읽기나 쓰기 둘 다 어느 레플리카라도 처리할 수 있게 하지만 문제는 위의 두개이다.
5. PB에서 문제가 발생했을때
1) 팔로워에게 장애가 발생하면? catch-up recovery.
장애가 발생하면 가장 먼저 장애를 탐지해야 한다 - 타임아웃을 통해 탐지한다.
1초마다 alive메세지를 보내오면 리더가 그걸 받는다. 만약 3초정도 메세지가 오지 않으면 팔로워가 문제가 생겼다고 알 수 있다. 재부팅/재접속 등의 조치를 취한다.
장애가 발생한 서버는 장애발생시간동안 업데이트가 안 되고 있다.
그 레플리카는 장애에서 복구된 후 - 다른 레플리카와는 다른 내용을 소유하게 된다. 동기화를 시켜줘야 한다.
- 레플리케이션 로그 = 업데이트된 기록. 수행이 되었던 쓰기 기록들.
재부팅 이후에는 레플리케이션 로그부터 재생시킨다.
2) 리더에게 장애가 발생하면? failover.
리더에게 답장(하트비트 메세지)이 오지 않으면(타임아웃) 장애가 발생했다고 판단한다.
리더에게 장애가 발생한 경우: 리더 일렉션이 발생한다.
- 몇가지 대표적인 예
(1) 최초로 장애가 발생함을 발견한 팔로워가 자신이 리더의 역할을 수행한다고 전파한다.
(2) 사전에 미리 정의해둔 계승순위를 따른다. (주키퍼에서 사용하는 방식)
- 쓰기 요청이 리더에게 가게끔 설정하고, 팔로워들이 새로운 리더를 인식하게끔 하는 절차가 필요하다.
6. failures를 다루는 것의 어려움
1) 타임 아웃 딜레마 - detection
3초동안 답장이 없으면 장애가 발생했다고 가정한다.
그러나 장애가 발생한 것과 - 메세지 타임아웃 발생 사이에서 직접적인 인과관계가 있는 것은 아니다. 정상적으로 작동하고 있는데 네트워크의 문제 때문에 오래 걸릴수도 있다.
2) Split brain problem - failover
장애를 먼저 탐지한 레플리카가 리더가 되는 경우. 리더에게 장애가 발생해서 0.001초 차이로 두개의 팔로워가 발견했을 때. A가 "내가 새로운 리더야! 장애가 발생했어!" B도 "내가 새로운 리더야! 이하생략"
즉 동시에 리더를 탐지하고 동시에 리더를 선언하면: 둘 다 자신이 리더라고 생각하게 된다.
+ 이때 리더가 멀쩡히 살아있으면 문제가 더 복잡해진다.
failover이 자동화 되어 있기 때문에 발생하는 문제.
때문에 장애 탐지까지는 타임아웃으로 자동화를 하지만, 장애를 복구하는 것은 수동으로 한다.
! Redis에 관한 Case study
- 리더 베이스 레플리케이션을 사용한다.
- 하나의 마스터와 여러개의 레플리카들이 존재한다.
1) 읽기는 모든 레플리카들이 처리할 수 있다. (높은 처리량)
2) 쓰기의 경우 마스터만 처리한다.
- 문제점: 데이터 동기화가 제대로 되지 않아서 일관성이 없다. (옛날 데이터를 읽을 수 있게 된다)
03. 일관성 Consistency
1. ACID properties란?
: Atomicity, Consistency, Isolation, Durability.
(1) Atomicity
전체 트랜젝션(a=3, b=4, c=a의 작업처리를 하나로 묶은 것)은 성공할것은 성공하고 실패하는 것은 실패한다는 것.
a, b까지 진행했다가 c에서 실패했으면 어중간하게 처리된다. 반영될거라면 성공하면 다 성공한것으로, 실패한다면 다 실패한 것으로 처리한다.
(2) Consistency
일관성. 말 그대로 같아야 한다.
계좌이체 예시가 많다. A 1000원, B 500원. > -500, +500. > A는 500원, B는 1000원.
데이터의 값이라는 것은 반영되었으면 전과 후가 일관성 있게 동일한 값이 반영되어야 한다.
(3) Isolation
읽기/쓰기를 진행할 때, 특정 트렌젝션을 진행하는데 다른 트렌젝션이 끼어들면 안 된다.
독립적으로, 서로간의 간섭이 없어야 한다.
(4) Durability
트렌젝션이 성공한 이후에 장애가 발생했다면: 그 데이터의 값이 트렌젝션을 반영하고 있어야 한다.
100만원을 입금한 이후 은행의 데이터센터에 장애가 발생했다고 하자. 복구했더니 계좌에 0원이 찍혀있다면?
트렌잭션이 성공했다면 장애 발생 여부와 상관없이 그 값이 유지되어야 한다.
* 게임회사의 경우 롤백이라는 단어가 존재한다.
게임서버가 하루마다 데이터를 백업해서 그렇다. Durability 지원하지 않는 것. 지원하는 경우 실시간으로 바로바로 데이터를 전송하고 저장할 수 있다.
게임 유저들이 강력하게 항의하지 않으니까 별로 투자하지 않는 것. 그러나 은행에서 같은 사태가 발생하면 정말로 돈이 사라지기 때문에 난리가 날 것이다.
2. 분산시스템에서 consistency는 무엇인가?
1) Consistency reads. 일관성 있는 읽기.
성신이라고 하는 키의 가장 최근의 데이터가 '김수룡'이라면, 어디에서 어떻게 읽든 그 데이터만 리턴되어야 한다.
2) Inconsistent reads

-> 프라이머리 백업 구조.
쓰기는 리더가 처리하지만 다른 팔로워들도 읽기는 처리할 수 있는 구조.
독일과 아르헨티나가 1:0으로 값을 업데이트했다고 하자.
팔로워들에게 업데이트 메세지를 전달.
- read-write conflicts
앨리스와 밥이 데이터를 조회한다고 하자.
앨리스의 읽기 요청은 모든 레플리카가 처리할 수 있으니까: 팔로워 1로 읽었다. 팔로워 1의 데이터는 최신의 데이터. 업데이트 메세지 > 읽기 요청 메세지보다 더 빨리 왔으니까.
밥의 읽기 요청은 팔로워 2에서 처리되었다. 이때 팔로워 2의 경우는 리더가 전송한 업데이트 메세지보다 < 읽기 요청이 더 먼저 왔기 때문에, 0:0이라는 데이터를 읽어버리게 된다.
최종 경기 결과는 앨리스 "독일이 우승했대!" 밥 "어? 경기중이라는데?"
둘은 동일한 데이터를 읽으려고 했지만 서로 다른 데이터를 읽게 된다.
쓰기 요청이 모든 레플리카에 도달하는 시간이 다를 수 있기 때문에 - 읽기 요청이 업데이트 전에 도착해버리면 클라이언트들마다 읽게 되는 데이터가 달라진다.
3. Linearizability (Strong Consistency, SC)
강한 일관성. SC.
이것을 지원하는 시스템은, 어떤 레플리카가 오래된 데이터를 가지고 있을지언정, 항상 최신 업데이트 값을 돌려준다.
일관성 없는 읽기는 동기화가 깨져있기 때문에 클라이언트가 가져가는 데이터가 서로 달랐다.
하지만 이것을 지원하는 시스템은 데이터의 값이 다른 순간이 발생하더라도: 결과적으로 클라이언트는 최신의 데이터를 가져간다.
구축하기 굉장히 힘들다. 일관성 없음 문제가 발생하는 이유는: 읽기 요청을 로드밸런싱처럼 자유롭게 선택해서 보냈기 때문이다.
때문에 강한 일관성을 위해 팔로워가 가지고 있는 데이터가 최신의 데이터인지 확인하고 결정해서 보낸다.
가장 높은 수준의 일관성 레벨.
레플리카가 여럿이더라도 클라이언트 입장에서는 단 한 서버만 존재하는 것처럼 느껴진다.
- atomic consistency, immediate concistency, external consistency 등 다양한 용어로 불린다. But SC가 가장 보편적이다.
- 하나의 트렌젝션은 아이솔레이션을 제공한다 <-> 무조건 최신의 데이터를 읽어야 한다는 목적과 충돌!
phantom reads를 발생시킨다.

1이 왜 리턴되는가? C에서 x가 1로 업데이트 되어버려서. 이때 A는 그냥 읽었을 뿐인데 0>1로 변경된다.
4. Linearizability을 어떻게 구현하는가?
1) 리더 베이스 레플리케이션
- 리더가 모든 읽기/쓰기 요청을 처리한다.
- 또는, 읽기 요청이 오직 최신의 업데이트를 반영했다고 판단되는 레플리카로 가야 한다.
로드 밸런싱으로 처리되지 않고, '최신의 데이터인지 고려해서 분배하는 것은' 어려운 일이기 때문에 거의 사용되지 않는다. 심플하게 리더가 모든 요청을 처리하는 방식이 가장 많이 사용된다.
2) 체인 레플리케이션
쓰기가 A=2를 처리하고 있는데 읽기는 A=3으로 읽어갈 수 있다. 즉, Linearizability하지 않다.
그러나 SC를 지원한다는 표현을 사용한다. 왜?
쓰기 요청에 대한 최신의 데이터라는 정의가 다르기 때문에.
- 관점의 차이
최종적으로 쓰기가 커밋이 되지 않았다고 하더라도 (그 사이에 어떤 레플리카는 최신 데이터/아닌 데이터가 진행중이다) 최신 데이터를 제공해야 한다는게 Linearizability.
<-> 최종적으로 커밋이 되지 않은 데이터는 최종 데이터라고 인정하지 않으며, 커밋이 되어야 최신 데이터라고 간주한다.
= 최신 데이터의 정의: 커밋이 된 것만 인정. <-> 커밋이 되지 않은 쓰기 진행중인 데이터 인정.
3) 리더리스 레플레이케이션
Read-write conflicts: object invalidation

쓰기 요청이 맨 앞의 서버에서 처리되는 것 뿐. 리더가 아님.
어떤 경우에도 클라이언트가 항상 최신의 데이터를 읽어야 한다는 말에는 성능에 대한 이야기가 없다.
쓰기가 최종적으로 커밋이 될 때까지 읽기 자체를 막아버린다.
읽기의 레이턴시는 늘어나지만 Linearizability는 성립한다.
+ 타임 스탬프 방법
1보다는 2가 최신, 2보다는 3이 최신.
클라이언트가 두개가 있으면 하나는 읽기/하나는 쓰기만 보낼때, 타임 스탬프가 동기화되지 않는다.
nodeID와 타임스탬프를 조합해서 사용. 버전정보를 관리해야 한다.
! 분산시스템은 이론적으로 연구가 많이 되었다. 거의 모든 것을 Lesile Lamprot가 만들었다. 마이크로소프트에서 연구원으로 재직. 2013년에 튜링상을 수상.
5. 일관성 레벨과 모델
1) 트레이오프 관계
성능을 올리고 싶으면 일관성을 포기.
일관성을 올리고 싶으면 성능을 포기.
2) 일관성 수준: CS가 가장 높은 수준. 그보다 낮은 일관성이 다양하게 존재한다.
- Strict consistency: Linearizability한 모델.
- Sequential consistency: 실행 순서만 신경쓴다.
- Casual consistency: 직접적으로 관련된 오브젝트의 실행 순서만 신경쓴다.
3) Weak consistency
- Read-yout-writes consistency: 적어도 A=3이라고 입력하면 read(A) = 3으로 읽게 되는 것.
- Eventual consisteny: 업데이트에는 오랜 시간이 걸리지 않고, 금방 일관성이 되는데 성능을 약화시킬 필요는 없다는 것.
콘서트 티켓팅에서 빈 좌석이라고 딱 뜨는 것. 모든 클라이언트가 동일한 화면을 보는 것이 아닌(Linearizability), 클릭하면 이미 예약된 좌석이라고 뜨는 것.
옆에 있는 사람은 조회해보니 경기가 끝났다고 하는데 조회해보면 경기중이라고 뜸. 일관성 있지 않음.
하지만 "새로고침 하면 되잖아?"
쓰기 요청이 커밋이 되기까지의 사이 순간에서만 일관성이 깨지게 된다.
언젠가는 커밋이 되면서 모두 동일한 데이터를 읽게 되니까 - 잠깐 동안에는 비일관성이 발생해도 결국 다 일관성 있어진다. 굳이 성능을 그렇게까지 악화시키면서 동일한 수준의 일관성을 제공해야 하는가.
4) 그러면 CS를 왜 쓰는거야?
대부분의 경우 Eventaul을 써도 좋지만, CS가 중요한 분야가 있다. 특히 금융.
Weak consistency가 보통은 충분하지만 어떤 어플리케이션에서는 충분하지 않다.
절대적으로 옳은 솔루션은 존재하지 않는다.
- 최종
분산데이터베이스 시스템을 구축할때는 그냥 복제하고 하는 것에서 끝나지 않고 일관성을 고려해야 한다.
대부분의 데베 시스템이 일관성 시스템을 지원한다.
MySQL은 깊게 들어가면 상당히 딥하다!
'강의 정리 > 분산시스템' 카테고리의 다른 글
| 분산시스템 (7) Fault tolerance (0) | 2024.04.15 |
|---|---|
| 분산시스템 (6) Consensus (0) | 2024.04.08 |
| 분산시스템 (4) 분산시스템과 캐쉬 (0) | 2024.03.25 |
| 분산시스템 (2) 분산시스템의 기초 (0) | 2024.03.19 |
| 분산시스템 (3) 커뮤니케이션 모델과 로드 밸런싱 (0) | 2024.03.18 |


