- 주제
Caching: 로드 밸런싱의 일종.
쏟아지는 요청을 골고루 분배하기 위함.
캐싱에 대해 이해하기 위해서는: 먼저 분산시스템 구성에 대해 알아야 한다.
컴퓨터 구조 시간에 배운 개념. 캐쉬라는 것은 특정 도메인이 아니며, 범용적으로 적용되는 매커니즘이다.
- 분산 데이터베이스에 대해서
- RDB vs NoSQL
- Relational Databases(RDB): 관계형 데이터베이스.
우리가 주로 알고있는 데이터베이스. 엑셀처럼 구성되어 있다.
투플, 관계로 구성. 모든게 테이블에 소속.
Oracle DB, MySQL, MariaDB 등.
ex. Select * From sswu.sstudents WHERE name = "김수룡"
- NoSQL = key-vaule stores: SQL을 사용하지 않음.
키와 값이 페어이며 이것이 전부다. 매-우 빠르다.
RockDB, Memcached, Redis, LevelDB 등.
ex. key = "김수룡", value = "20, 20230001"
get("김수룡"), put("김수룡", "20,20230001")
현대의 대규모 온라인 서비스에 주로 사용된다.
서비스가 성장할수록 MySQL은 느리기 때문에 필연적으로 NoSQL로 변경해야 한다.
* 특히 웹서비스 제작시 고객수가 아득해지면 어느 시점에서는 키 벨류 스토어로 갈아엎어야 함.
* 무신사라고 하는 회사도 처음에는 소규모의 기업이었으나 - 성장하면서 접속 웹사이트의 고객수가 늘어나며 기존으로는 커버가 불가능해졌다. NoSQL 도입.
* 백엔드 개발자 필요조건의 경력직에 보면 MySQL을 할 줄 아는 사람을 찾지 않는다. 흔히 가고싶어하는 대기업은 고객의 수가 많기 때문에 인프라의 사용이 확장성/고성능인 기술 요구. RDB를 사용하지 않음.
* 그럼에도 불구하고 RDB는 많이 쓰임. 은행/증권사에서. 기업 내부에서도. 은행 전산지 채용 공고를 보면 일반적인 백엔드 개발자뿐만 아니라 관계형 데이터베이스 지식자 요구.
* 오직 소수의 사람만이 사용할 수 있음.
인메모리 데이터베이스 지원.
모든 데이터를 전부 메모리에 올려놓음. 디스크에 저장하면 CPU 요청에 의해 소요되는 전달 시간이 압축됨.
* RDB가 SSD에 저장되면 느림*느림=진짜 느림. 이를 key-value로 메모리에 저장하면 500-1000배 차이남.
* RocksDB: SDD/HDD 저장 전문.
* redis/Memcached: 메모리 전문. 점유율 1, 2위. 압도적인 빠름 때문. 특히 레디스.
- 분산된 데이터베이스
: 데이터베이스가 여러 서버에 분산.
- 왜 여러 서버에 분산하는가? 크게 3가지 이유가 있다.
1) 성능
2) tolerance
서버가 여러대니까 성능이 좋아지고, 장애 대처에도 도움이 됨(일반론적인 이야기).
순수하게 데이터베이스 측면에서는 3) limited storage size 서버 용량이 제한되어 있기 때문.
* 요즘 서버 용량은 정말 큰데? 우리가 그냥 생각하는 데이터의 양=/=실제 데이터 요구량.
유튜브를 예시. 하루에 올라오는 동영상의 양만 수백 테라바이트를 훌쩍 넘음. 서버 한대에 저장할 수 있는 양이 제한됨.
서버를 많이 연결하면? 그 또한 한계. 모든 데이터는 PCI 링크를 타고 연결하는데 PCI 대역폭은 제한되어 있음. 성능상의 병목현상 발생.
- 각각의 서버들이 여러개의 partitions/shards 보유.
데이터베이스를 분할해놓은 것.
* 2024년의 날씨 데베를 구축할때) 월별로 나눈다면 1월이 하나의 파티션, 2월이 하나의 파티션 등. 큰 데이터베이스를 잘게 쪼갠 것.
- 데이터 파티셔닝 Data partitioning (=sharding)
- 어떻게 데이터를 쪼개는 거야?
- 각각의 데이터 그룹을 partition/shard로 부른다.
- 오늘날, 우리는 다양한 파티셔닝 기술을 볼 수 있다.
- 데이터를 쪼개는 기준은 디자이너 마음이지만 거시적인 기준 두가지 존재.
: 종적 파티션/횡적 파티션.

- Vertical partitioning횡적 파티션
: 테이블을 수직으로 잘라서, 관련된 데이터들을 가진 작은 테이블들을 만든다.
- Horizontal partitioning종적 파티션
: 테이블을 가로로 잘라서, shards로 불리는 조각으로 만든다.
각각의 shard는 분리된 저장 서버에 따로 저장된다 .
- Range partitioning
: 데이터를 범위로 나누는 것.

- Hash partitioning
: 해쉬값을 기준으로 나눔.

=> 데이터 유형에 따라 둘 중 하나를 선택한다. 데베 설계자가 잘 판단할 것.
- Data locating 데이터 로케이팅
파티셔닝을 하게 되면 저장되는 데이터가 서버마다 달라진다.
이때 로드 밸런싱의 기본 가정: 요청이 어느 서버에서 처리가 되어도 상관없지만 파티셔닝을 하게 되면 불가능하다.
원하는 데이터가 A에 있는데 B/C에 가게 되면 데이터를 찾지 못한다. 즉, 데이터가 어느 위치에 있는지 알아야 한다.
요청된 데이터가 어느 서버에 있는지 어떻게 알 수 있을까?
- Stateful vs Stateless
찾고자 하는 데이터가 어디에 있는가를 알아야 함, 수정관에 가기 위해 수정관이 어디에 있는지를 알아야 하는 것과 동일.
데이터 위치를 알아야 하니 로드 밸런싱이 사용되지 못함.
로드 밸런싱은 Stateless하고, 파티셔닝을 사용하게 되면 Stateful해야 한다.
- State=상태정보. 어떤 임의의 시점의 시스템의 상태/정보.
데이터의 값이 무엇인지, 어디에 저장되어 있는지. 서버가 어떻게 행동할지를 결정하는데 필요한 정보. 사용 가능한 자원의 양 등, 다양한 정보가 상태정보가 될 수 있음.
- Stateful servers: 서버가 상태를 유지하면서 상태정보를 저장.
서버가 상태정보를 기억하고 있는 경우. 그 상태정보에 기반을 두고 처리를 진행.
- Stateless servers: 서버가 어떤 상태정보를 저장하지 않음.
=> 로드 밸런싱은 Stateless로 진행된다. 분산시스템은 Stateful하기 때문에 로드 밸런싱은 사용 불가.
* 파티션한 서버를 여러개 복제하면: 모든 서버가 동일한 서버정보를 가지고 있으면 사실상 Stateless가 되기 때문에 로드 밸런싱 가능. 하지만 일반적으로 그러지 않음.
- 내가 요청한 데이터의 위치를 어떻게 찾느냐.
1) Client-based approaches
: 클라이언트가 테이블을 사용해 데이터의 위치정보를 유지하고 있다.

클라이언트에 테이블 정보가 주어졌을 때, read(151) 입력.
어떤 서버에 보낼지 모르겠을때 자신의 테이블 확인, 10.0.102의 목적지 IP주소 확인.
- 성능상의 바틀랙이 존재하지 않음(클라이언트가 바로 확인).
- 모든 클라이언트가 동일한 테이블을 유지하고 있어야 함 -> 재구성시 모든 주소가 변경되기 때문에 클라이언트 모두에게 변경 사실을 고지해야 함. 클라이언트는 서버보다 훨씬 많을 수 있음. 동기화 문제 발생.
=> 동기화 문제때문에 사용하기 어려움.
2) Coordinator-based approaches
:lookup 테이블을 클라이언트와 서버 사이 코디네이터가 보유. 클라이언트가 코디네이터를 방문해서 룩업 테이블을 참조한 다음 서버를 찾아간다.
- 장점: 동기화 문제 없음. 하나의 코디네이터만이 룩업테이블 보유.
- 단점: 성능상의 이슈. 퍼포먼스 병목(바틀랙) 문제 발생, 모든 요청이 코디네이터를 방문해야 하니까.
* 중요! 한 기술의 한계는 다음 기술은 한계점을 해결할수는 있어도 아무런 단점이 없는 것은 아니다. 트레이오프 관계.
-> 발전된 Coordinator-based approaches
- 아파치 주키퍼의 코디네이션 서비스.
- 클러스터에 있는 여러가지 메타데이터를 트래킹하고 다양한 정보 제공.
- 주키퍼는 기본적으로 key-value stores.
- 코디네이션 서비스라고 하는 것은 분산시스템을 종합적으로 지원해줌.
- 서버에 장애가 발생했는지 탐지하는 역할을 함. 하트비트 메시지.
1초마다 패킷을 하나씩 보내는데 3초동안 메세지가 보내지지 않았다면: 주키퍼가 탐지. 서버가 장애가 발생했다 -> 장애 발생 서버를 제거하고 재구성함.
- 분산시스템을 관리하기 위한 여러가지 서비스를 제공 + 장애 탐지 서비스 등을 제공.

* - 레인지 파티셔닝(다른 파티셔닝을 사용할수도 있음)
: 각각의 오브젝트에 대한 주소 제공. 0번과 3번과 6번 9번은 노드0이 들어가 있음. 물리적인 하나의 서버에 여러가지 파티션이 들어갈 수 있음.
캐쉬이야기는 도대체 언제 하느냐? 지금부터.
분산시스템에서는 로드 밸런싱이 불가능하다. 그렇다면 로드 밸런싱을 사용하지 않는가?
요청이라고 하는 것이 데이터가 위치한 서버로만 갈 수 있다면: 문제가 발생하는가?
발생한다. 어떤 데이터는 다른 어떤 데이터보다 훨씬 유명하기 때문에.
* 예를 들어 뉴진스의 뮤직비디오는 5천만 조회수, 교수님의 영상은 10 조회수. 즉, 모든 데이터는 평등하지 않다.
- 모든 데이터는 popularity는 skewed이다. 또한 굉장히 극단적이다.
- 이상적으로는 모든 서버가 동일하게 활용되어야 하겠지만, 현실은 아니다.
분산시스템의 목표는 모든 서버가 1초도 쉬지 않고 일을 처리하는 것 -> 기본 전제는 popularity가 동일해야 한다.
* 서버별로 파티셔닝이 다르다(=저장하는 곳이 다르다).
1초에 요청이 10개씩 오는데 100개를 수용할 수 있다면 사실상 놀고 있는 것. 그것이 문제는 아니라고 해도, 예를 들어 뉴진스 컨텐츠가 있는 곳에 1초에 천만개가 들어오는데 한 서버는 백만개만 처리할 수 있고 모든 서버를 합쳐서 천만개가 수용 가능하다고 하자.
그래도 데이터 로컬리티 때문에 분배가 불가능하다.
-> 어떻게 해결하지?
서버 각각의 처리량을 정렬. Uniform populatity는 고르게 분배되지만 Skewed popularity는 불균형하다.

그럼에도 불구하고 고르게 하고 싶다면?
1) 가장 단순한 접근법: 데이터 파티션을 재구성한다.
가장 popularity가 높은 데이터를 나눠서 다른 서버에 이동시킨다.
그래도 가장 popularity가 높은 데이터는 서버 하나로 감당할 수 없는 처리량을 요구할 수도 있음.
- 해답은 Caching 사용!
원래 데이터를 저장하던 곳보다 더 빠르게 접근할 수 있는 장소에 데이터의 카피를 저장하는 기술이다.
: 가장 최근에 액세스 한 것을 저장한다. 만약 A란 데이터가 요구되는데 캐쉬에 A란 데이터가 있으면 바로 가져와서 사용. 서버 로드가 줄어듬.
기본적인 컨셉은 CUP의 캐싱을 따온 게 맞음. 메모리까지 가지 않고 캐쉬에 방문해서 CPU의 명령을 처리하는 것.
- 캐쉬의 두가지 방법
-> Look-aside architecture

- 별도의 캐쉬 로드를 만든다.
- 높은 popularity 데이터를 캐쉬에 복제해 넣는다 = Top-K 데이터를 캐쉬에 넣는다(가장 popularity가 높은 데이터).
- 모든 요청은 일단 캐쉬를 방문하게 한다.
캐쉬에 요청한 데이터가 있는지 확인하고, 있으면 가지고 돌아가고 - 없으면 데이터가 있다고 말해지는 서버로 방문해서 가져온다. Cache hit이 발생하면 가져오면 된다.
- 장점) 캐쉬에서 처리해주면서 천만 요청이 들어오면 삼백만 요청만 받아들이게 된다.
- 단점) 캐쉬 미스 패널티 존재.
클라이언트가 무조건 캐쉬를 방문해야 하기 때문에 캐쉬 힛이 발생하지 않으면, 캐쉬 로드를 방문하지 않았어도 됐는데 방문된 것이기 때문에 패널티가 발생.
그래도 사용되는 이유는 100개의 요청이 들어왔을 때 99개는 파퓰러가 높은 데이터가 들어오고 예외가 나머지 하나이기 때문.
-> On-path look-through architecture
위의 문제를 해결하기 위해 등장! 이상적인 방법은 패널티가 없는 것이다. 없앨 수 있을까?
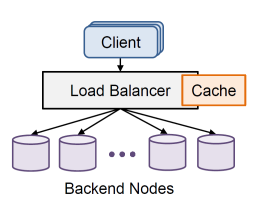
- 코디네이터에 캐쉬를 붙이는 것.
코디네이터는 종합 프로그램이며 어차피 방문해야 하기 때문에: 방문하는 김에 살펴보게 됨.
- 장점: 캐쉬 미스 패널티가 사라진다.
- 단점: 기존에는 캐쉬 노드와 코디네이션이 분리되어 있었기 때문에, 코디네이션이 장애가 발생하는 것과 캐쉬 노드가 장애가 발생하는건 다른 상황이었으나 - 둘이 함께 있으면 함께 먹통이 되어버린다.
전문용어로 Fatesharing problem이다. 물리적인 서버가 장애가 발생하면 서버에 관련된 모든 기능들이 죽어버리는 것 의미.
즉 장애 발생시 취약!
결국은 선택의 문제이다.
패널티가 발생하더라도 장애 발생 공통 문제를 피하고 싶으면 전자, latance가 더 중요하면 후자.
주의 깊게 생각해야 한다. 모든 솔류션은 장점과 단점을 함께 보유하고 있다. 단점을 극복하기 위한 기술 또한 또다른 단점 보유하고 있다.
- 캐쉬에 구체적으로 몇개를 저장해야 하는가?
캐쉬에는 (N log N)개를 저장하면 좋다. (!!! 중요 !!!)
서버가 64개라면 64*1.81=116개 정도 저장하면 좋다.
N=서버의 개수. 데이터 셋의 사이즈가 중요하지 않고 서버의 갯수가 중요한 것(파티션의 개수).
데이터의 용량과는 전혀 관련 없음.
이는 직관적으로 반하는 부분이다.
데이터셋이 1만개 정도 있는데도 상관없다고? 상식에 위배되지만 그렇다.
데이터의 Popularity는 데이터 셋이 증가하면 증가할수록 극단적으로 변하게 된다. 왜 그렇게 되느냐? 일종의 자연계의 법칙같은 것. 2:8의 법칙.
'강의 정리 > 분산시스템' 카테고리의 다른 글
| 분산시스템 (7) Fault tolerance (0) | 2024.04.15 |
|---|---|
| 분산시스템 (6) Consensus (0) | 2024.04.08 |
| 분산시스템 (5) 복제Replication/일관성Consistency (0) | 2024.04.01 |
| 분산시스템 (2) 분산시스템의 기초 (0) | 2024.03.19 |
| 분산시스템 (3) 커뮤니케이션 모델과 로드 밸런싱 (0) | 2024.03.18 |


